The Big Picture
The are two main components in reinforcement learning:
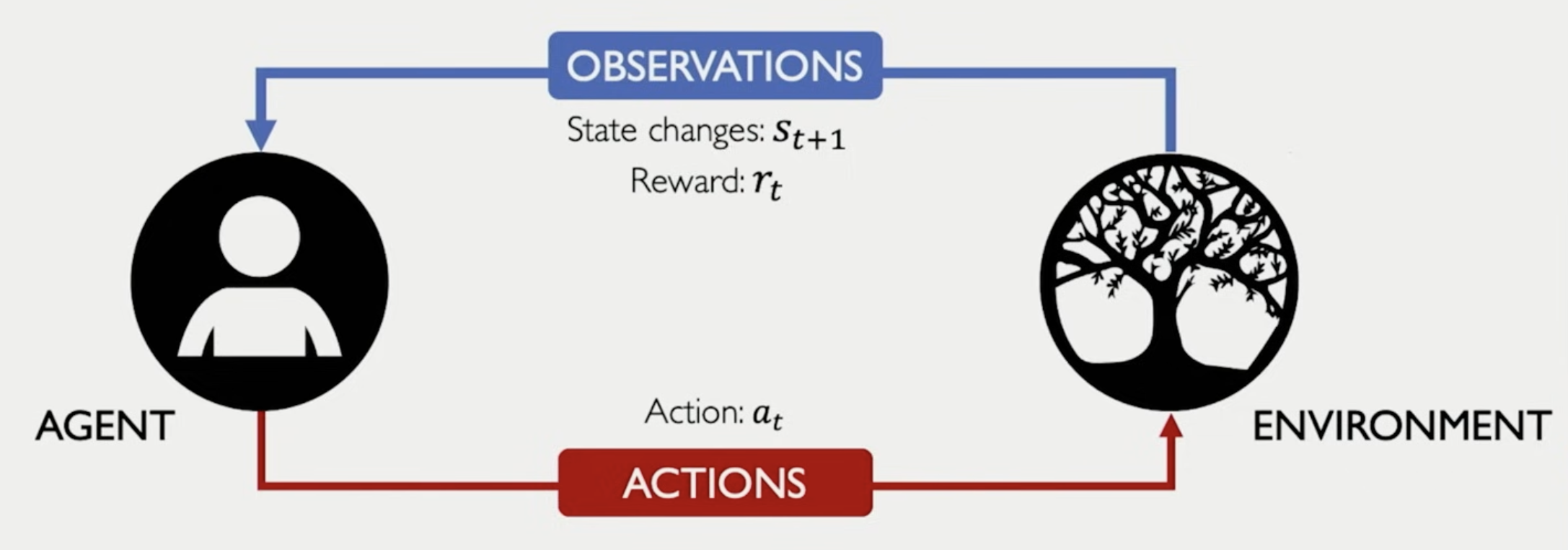
- A set of states
- A set of actions
- A state transition function , which gives the next state after taking action in state
- A reward function that gives immediate reward after taking action in state
Rewards
The most naive way to define the total reward is to simply sum up all the immediate rewards:
However, the future rewards are usually less valuable than the immediate rewards. And thus we introduce a discount factor to reduce the value of future rewards:
Q-Function
The semantic of Q-Function is capture the expected total future reward for an agent taking action in state
Policy
Agent need a way to choose action to take in each state. Which is done by a policy
which means that the policy should choose an action maximize future rewards.